
1. Introduction
The growth and availability of big data and data science tools has been met with enthusiasm and caution. Administrative data generated in healthcare, criminal judicial systems, and child welfare systems, to name a few, are used to develop risk scores and inform decision-making for social good. Some have argued that this form of human-tech interaction may lead to gains in efficiency in systems that operate over capacity (Redden, 2020). However, when it comes to data generated from the social interactions between people within their social structures, data has the potential to carry societal biases embedded in those interactions. Examples of bias in algorithms to inform health and social services abound (Anderson & Visweswaran, 2025). Additionally, case workers or other service providers tend to distrust black-box algorithms and don’t use them as expected (Kleinberg et al., 2018).
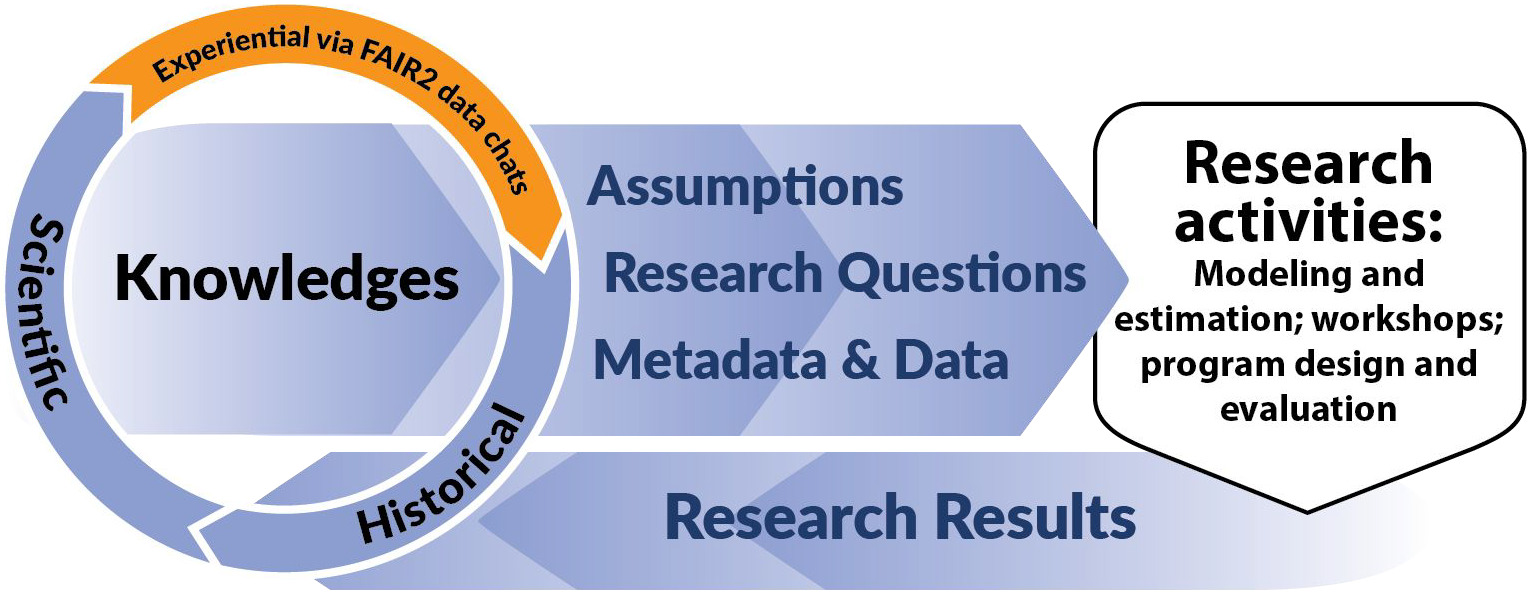
Lundberg and colleagues write, “A pivot to new sources of ‘big data’ creates an ever-greater need for clarity about the gap between the theoretical goal and selection issues that constrain the data available” (Lundberg et al., 2021, p. 30). Thus, no matter how big the data is, knowledge about the social interactions underlying the data-generating process is relevant to inform algorithm design and implementation if data technologies are to advance the public interest (Whicher et al., 2022). The FAIR2 framework aims to do just that (F. G.-C. Richter et al., 2023). FAIR2 expands on the established FAIR data principles (Wilkinson et al., 2016)—Findable, Accessible, Interoperable, and Reusable—by introducing four additional principles tailored for social data: Frame, Articulate, Identify, and Report, described further in Section 2.
This paper introduces FAIR2 Data Chats, a participatory research tool (PRT) developed under a Public Interest Technology (PIT) lens, aimed at integrating experiential knowledge in the social data to identify and address potential biases during the analytic process. PIT refers to the development, deployment, and governance of technology in ways that prioritize the public good, social justice, and ethical considerations (All Tech Is Human, n.d.). This definition applies to data science, where the development, governance and implementation of data-driven methods have the potential to impact social good, equity, and ethical outcomes. Public interest data science, then, aims to advance the public interest in a way that generates public benefits and promotes the public good. In this context, FAIR2 Data Chats constitute a tool for public interest data science by effectively enriching the metadata and data, the modeling assumptions, and ultimately, the research process with experiential knowledge.
Data chats, as a term to refer to conversations around data, are not new. The term “data chat” originally appears in the literature in reference to instructional interventions for teachers meant to foster data-driven decision making in education (Piro & Hutchinson, 2014). Piro and colleagues (2014) developed data chats for pre-service teachers with the goal of empowering their use of data to develop teaching interventions. In these meetings, educators analyzed data on standardized testing and course assessments and contributed their insights to create educational interventions. The interaction of experiential insights with data analytics to inform programs or policy is thus at the core of data chats.
Evolving from this first use of data chats in education, Milwaukee’s Data You Can Use organization (DYCU) implemented and developed a Guide to Data Chats defined as small-scale, community conversations about data designed to elicit residents’ perspectives and interpretations of such data. DYCU data chats “center[ing] residents’ knowledge, community understanding, and experiences in the understanding of quantitative data” (Cohen et al., 2022). This approach elevates the lived experience crucial to enrich the findings of research and allows researchers to learn from the community collaborators while sharing information. These examples of data chat methods focus on a meaningful, two-way flow of information to inform grassroots action for positive change in the community.
FAIR2 Data Chats discussed in this paper further leverage experiential knowledge, so that this knowledge, together with scientific and historical contextual knowledge, can inform the inputs of the data analytic process or research activity. FAIR2 Data Chats were originally developed as part of an effort to enrich PIT in research and curriculum. Our goal was to show the vital need of “social metadata” (Allen, 2020) to improve our awareness of potential biases in the data and guide students and researchers who may otherwise only have access to quantitative data and data science techniques, disconnected from individual and societal narratives.
To date, FAIR2 Data Chats have been used to inform metadata and data analytics in homeless services, food assistance programs, and to enrich the data on racial disparities in financial wellbeing for older adults (F. G.-C. Richter et al., 2024). Furthermore, FAIR2 Data Chats have been used to enrich research activities beyond data analytics. We implemented them in preparation for a research conference on advancing access to education and employment by people with physical disabilities. The aim of the FAIR2 Data Chat was to elicit community experiential knowledge that could inform conference panel discussions, so that these discussions could be truly relevant to those with lived experiences and most impacted (F. Richter et al., 2025). These varied applications of FAIR2 Data Chats speak to the flexibility of this PRT to integrate community knowledge into data science and broader research endeavors enriching all aspects of the process from the research questions, meta data, data to modeling decisions and assumptions (Figure 1).
The subsequent sections provide an introduction to FAIR2 Data Chats (Section 2); the methods and principles guiding the implementation of data chats within FAIR2 (Section 3); an application of FAIR2 Data Chats (Section 4); and results and concluding thoughts (Section 5).
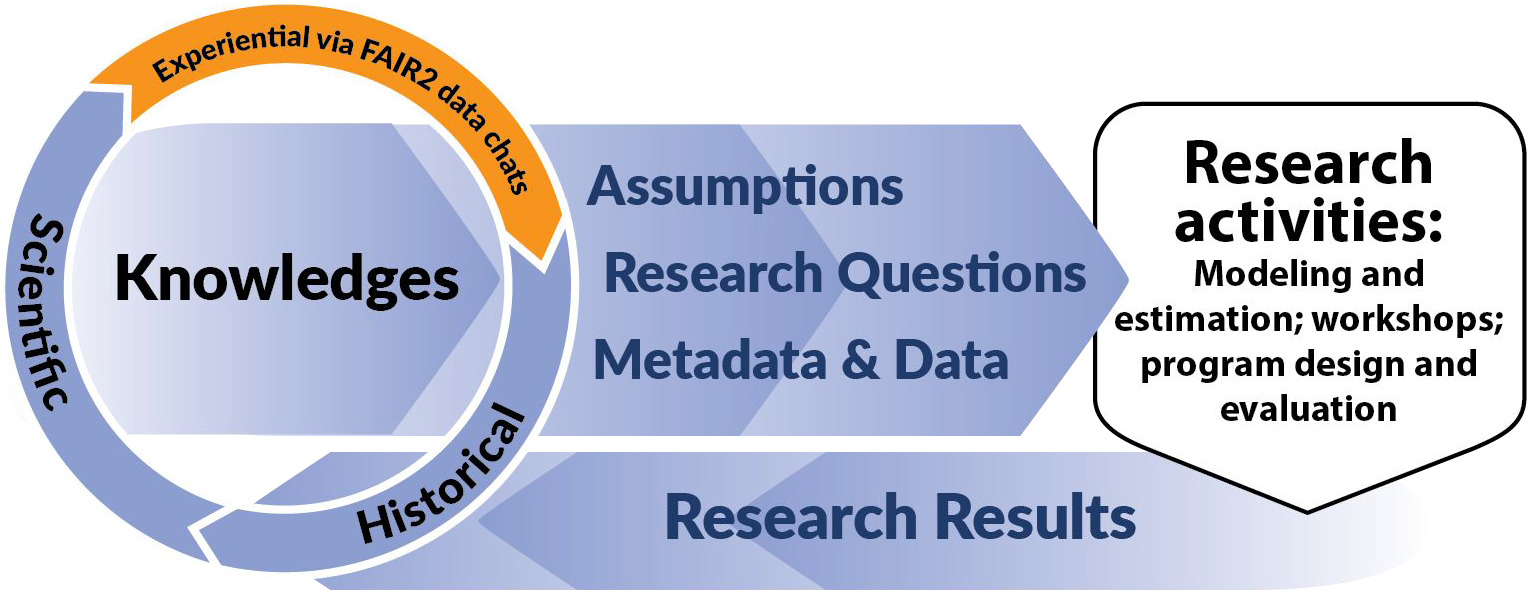
2. Data Chats within FAIR2
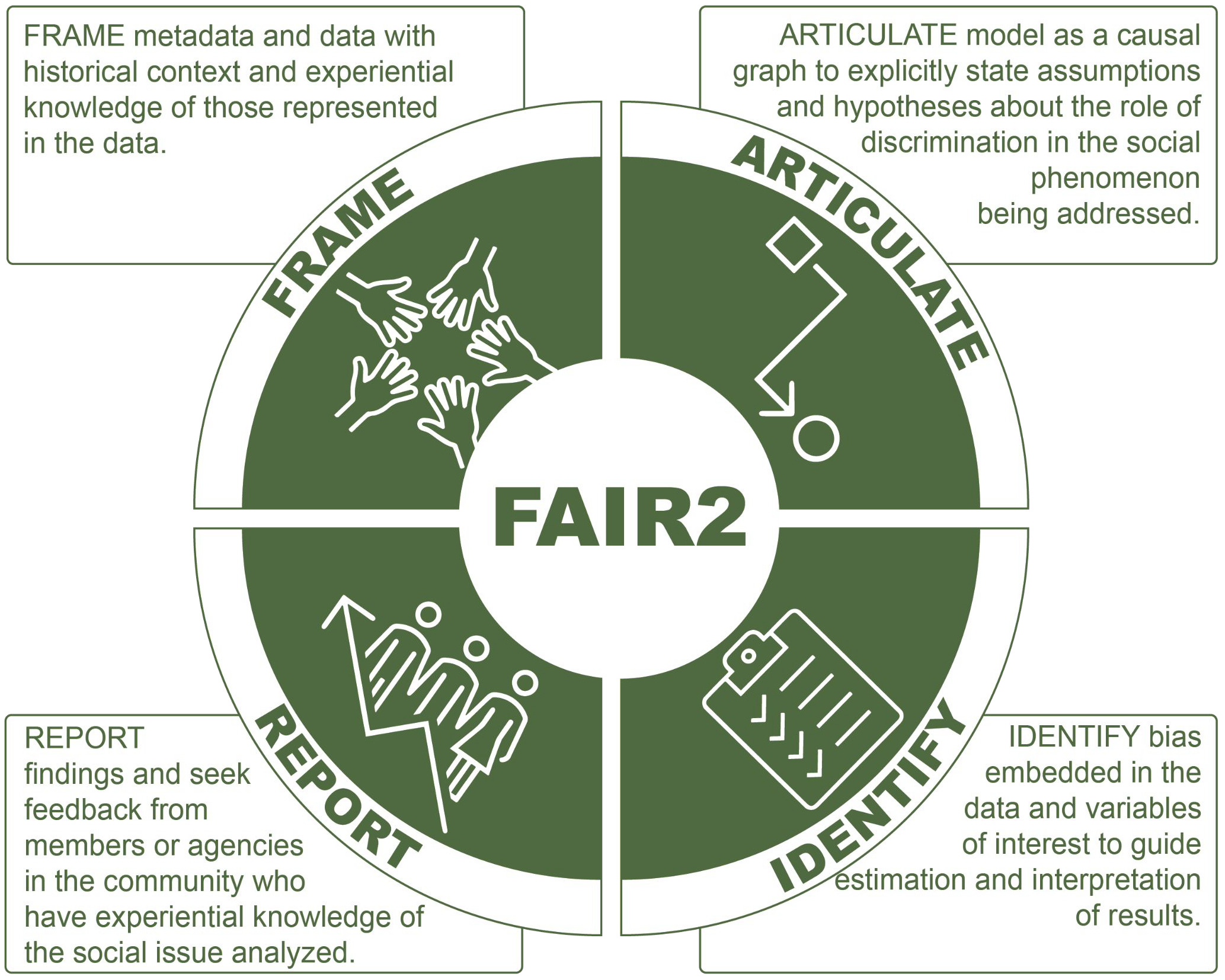
The FAIR2 framework was developed to advance PIT in data science, by integrating experiential knowledge throughout the data analytic process (F. G.-C. Richter et al., 2023). FAIR2 complements the ethical standards of FAIRification–Findable, Accessible, Interoperable and Reusable (Rocca-Serra et al., 2022; Wilkinson et al., 2016)–by adding four principles specific to social data (see Figure 2). FAIR2 stands for Frame (contextualize data with historical and community knowledge), Articulate (use this contextual knowledge to inform assumptions about data, metadata, and graphical models), Identify (identify discrimination bias embedded data and modeling) and Report (share and seek feedback from community members). FAIR2 acknowledges that data do not speak for themselves, that observational data often reflect discrimination in society, and that adopting an explicit approach to identifying and addressing such biases can enhance data science’s ability to promote the public interest.
FAIR2 builds on research in causal inference and important criticisms of “big data” science made by Pearl and Mackenzie (2018). It also draws from bias analysis in social sciences (Lundberg et al., 2021), health disparities research (Howe et al., 2022) and algorithmic fairness (Kleinberg et al., 2018). These foundations contribute to developing a community-informed understanding of the data generating process to guide its analysis.
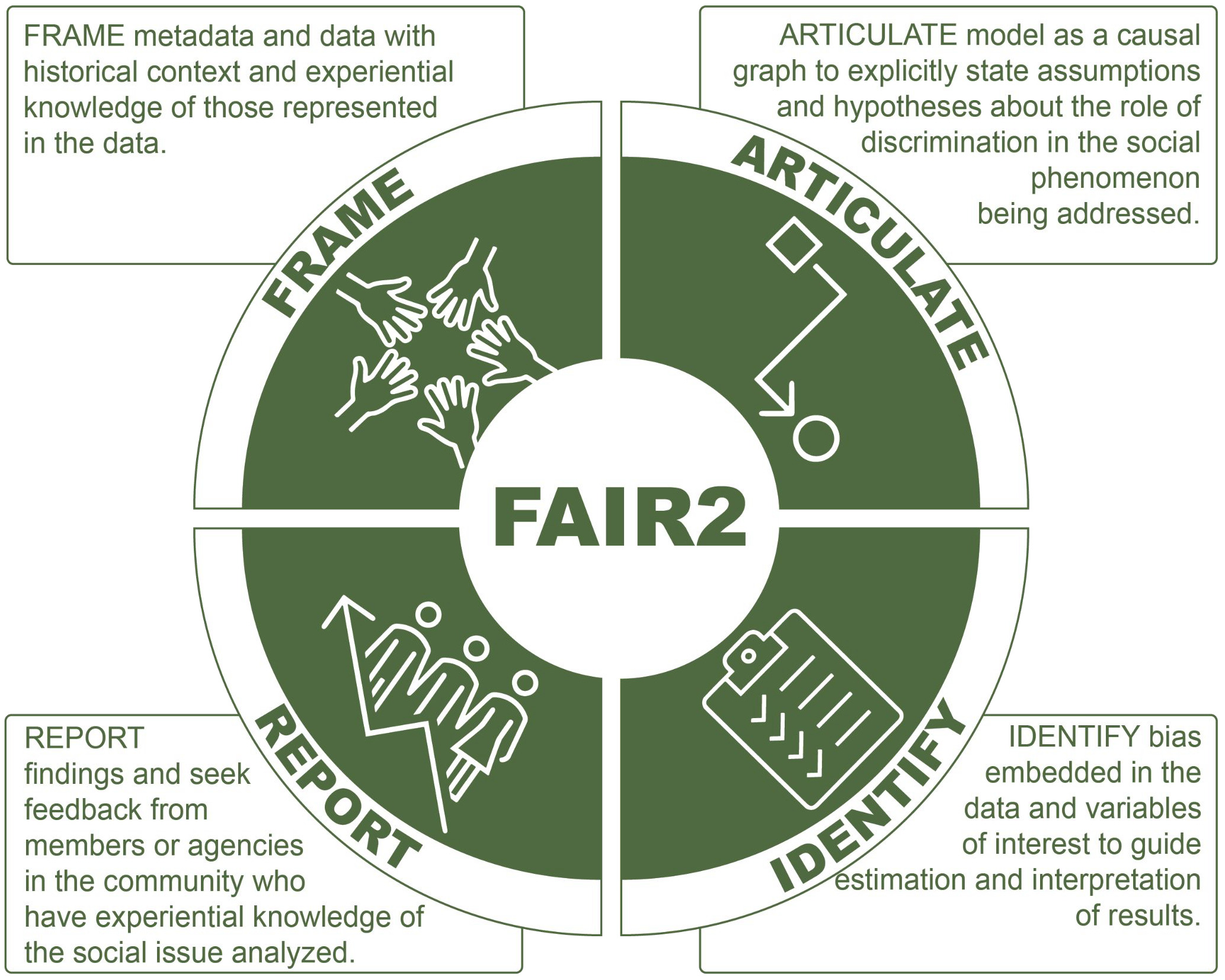
While FAIR2 is a framework, a FAIR2 Data Chat is a participatory research tool that can contribute to all four principles of FAIR2.
Frame: It is through conversations around data that people with experiences represented in the data can provide insights that help shape the assumptions under which the data will be analyzed.
Articulate: These insights are made explicit in the form of a system model, often depicted as a directed acyclic graph (DAG). The insights gathered through FAIR2 Data Chats serve to develop the systems model and can be presented back to participants for feedback. Graphical models break down communication barriers between people with experiential knowledge and researchers, as the articulation of a graph does not require statistical modeling expertise.
Identify: The lived experience is also a valuable source of experiential knowledge about the social interactions under which the data was generated (such as applying for shelter or being stopped by a police officer), which can help identify potential biases in the data (Identify). For instance, biases can occur if the analyst is unaware of some groups being underrepresented or overrepresented in the data. Bias can also occur due to misreporting of data elements (such as previous health diagnosis for lack of healthcare access).
Report: FAIR2 Data Chats build relationships with community stakeholders that provide avenues for reporting back and continuing to seek valuable feedback (Report).
FAIR2 Data Chats are meant to be organic collaborative encounters between a handful of researchers and people with experiences represented in the data, referred to as community collaborators. Organizers and community collaborators learn from each other; organizers share data and research, and community collaborators provide feedback based on their experiential knowledge. In that sense, they are quite different from focus groups and meet different objectives. Focus groups tend to be researcher-directed meetings, where participants are seen as research subjects rather than collaborators. While focus groups produce qualitative data from participants’ experiences, perceptions, and feelings, FAIR2 Data Chats share statistical summaries of the data and seek community collaborators’ insights regarding the way in which their experiences are represented in the data. This information enriches the metadata and informs the analytical process.
However, logistically, FAIR2 Data Chats and focus groups can resemble each other. Like focus groups, FAIR2 Data Chats are grounded in academic standards of ethical research and require a consent process approved by an IRB. As detailed in Section 3, the meeting takes place with a small group of community collaborators (ideally between 4 and 9) and researchers (two to three), who come together around a meal to discuss data visualizations and the way in which administrative data was collected from individuals. Unlike focus groups, FAIR2 Data Chats require reporting back to community collaborators on a synthesis of their insights and acknowledging their contribution in the products derived from the process.
FAIR2 Data Chats were piloted to enrich the metadata around two social welfare topics. One was related to food assistance data and is discussed in Richter et al. (2023). A second topic involved data that is collected when applying for emergency housing services. A set of resources, including the materials submitted to the IRB and outputs from both pilot FAIR2 Data Chats are available at cwru-dsci.org. The following section will draw examples from these two pilots to illustrate principles and implementation methods of FAIR2 Data Chats.
For ease of notation, “FAIR2 Data Chats” and “Data Chats” will be used interchangeably in the following section.
3. FAIR2 Data Chat Principles
The following principles guide the development and implementation of FAIR2 Data Chats:
Connection/Common Ground
FAIR2 Data Chat organizers seek to find common ground and connection between themselves and community members, which allows for two-way learning, where researchers and community collaborators can exchange knowledge and perspectives. By engaging with quantitative data and contextualizing them with personal experiences, community collaborators can challenge and shape the understanding of the data and the social processes that generate such data. In that sense, Data Chats can improve the quality of research by uncovering discrepancies between data and community experiences. This intentional effort to build connection begins to address historical inequities and exclusion. Power imbalances have historically harmed vulnerable groups, and problems like structural racism persist today and lead to reduced social capital, lower nutrition equity, and poorer overall health (Freedman et al., 2022; Gilbert et al., 2022). Because of this, marginalized communities, whose experiences are represented in the data, have been misrepresented or overlooked in data analysis. Engaging with these communities and incorporating their expertise in data discussions is a step toward doing better data analytics and advancing the public interest. By actively involving residents in interpreting data and informing the research process, Data Chats can contribute to more inclusive and equitable decision-making processes.
To give community collaborators a sense that Data Chats were different from their perceptions of or experiences with other academic research, we set out to create an intimate setting, ideally with more than three but less than ten community collaborators, who engage with the data but also share a meal and learn from one another.
An example of finding common ground was discussing unconventional methods to seek help over the phone for food assistance recertification. Community collaborators struggled to call an agency as phone wait times were long: "Somebody had a suggestion to get someone in Spanish." Another community collaborator said, “I’ll have to try that!" and one of our facilitators mentioned she spoke Spanish and had some success with this when calling another company. The group chatted about this and joked, "it’s like choosing your own adventure book where every ending is the bad one and you have to restart.” Another community collaborator summed up the conversation with "We’re airing out our frustrations! It’s therapy time." In another example, community collaborators were discussing what neighborhood was for them and displacement came up. A facilitator agreed this was an issue, bringing up a divisive local highway connector: “Look at how many people they kicked out of their houses to build the [Highway Project].” Community collaborators readily agreed, with one adding, another criticism of city planning: “You displaced all the people that had homes down there [in neighborhood] just to build bars?” Although neither example includes data collected or shared, the facilitator’s validation of these concerns led to a lighthearted tangent where many community collaborators shared a quick joke or remark about the situation, seeming to lead to a better connection.
Collaboration
Those participating in FAIR2 Data Chats are seen as collaborators who bring their subject matter expertise to enhance the research activity. Lived experience interacting with systems, programs, or social structures that generate the data being studied provides insights that academic research alone will likely miss.
Collaboration also fosters a sense of ownership and empowerment within the community. When community collaborators are actively involved in the analysis of data through Data Chats, they feel a sense of ownership over the process and the outcomes. They become co-creators of knowledge and solutions, rather than passive bystanders. Community collaborators revealed that they felt the Data Chat was the first time their voice was being heard: “Y’all really did listen to what we said. No one ever did that, and I want to thank you for that.”
Collaborative projects are often designed to disrupt existing power structures (Vines et al., 2013), and these empowering experiences can have a transformative effect on individuals and communities as they realize that their voices and contributions matter. Collaboration allows community members to become advocates for change, mobilize resources, and take collective action to address the challenges identified through Data Chats.
Furthermore, collaboration builds trust and strengthens relationships. By actively engaging with community collaborators and valuing their input, Data Chat organizers demonstrate respect and inclusivity. This fosters trust between the data organization and the community, creating a foundation for future collaborations and partnerships. When community collaborators see that their perspectives are valued and their voices are heard, they are more likely to actively participate and contribute their knowledge and insights. For example, during an initial Data Chat, researchers shared rates of poverty for the county and community collaborators did not initially believe that the numbers could be so low. After explaining that poverty data is collected through the census, three community collaborators stated they felt they had not been counted, including one who said, “We don’t answer the door for the census,” highlighting a historical concern with national datasets. In his book The Condemnation of Blackness, Dr. Khalil Gibran Muhammad highlighted the role of census and crime data in reinforcing stereotypes of Black people committing crimes, writing that despite the subjective nature of classifying people by skin color, “white social scientists presented the new crime data as objective, color-blind, and incontrovertible” (Muhammad, 2019, p. 4). Collaboration nurtures positive relationships, enhances communication, and builds a network of stakeholders who are invested in the well-being of the community.
Respect
Historically, health research and social policies have often overlooked—or even harmed—marginalized communities. FAIR2 Data chats help build trust and relationships. Although poverty is the top risk factor for poor health outcomes (Marmot et al., 2008), people experiencing poverty, such as those receiving emergency food benefits (Pratt et al., 2023) or experiencing unstable housing (Vamstad et al., 2022), have low levels of trust in social support agencies. Anticipating differences in ideas stemming from differences in experiences, and preparing to acknowledge those differences is essential for “partnerships where relationships are characterized by difference,” such as academic and community member partnerships (Eisenstadt & McLellan, 2020). This reinforces the importance of understanding and learning about the community engaged in the Data Chat and conducting sufficient preparation work prior to meeting with the community.
Trust
Trust is crucial for meaningful collaboration and effective community engagement, and projects that meaningfully engage the community have been described positively by community collaborators, demonstrated in a variety of projects such as group model building (Gerritsen et al., 2020), photovoice (Suprapto et al., 2020), and data walks (Jarke, 2019). By fostering relationships and demonstrating openness to correction and learning from community expertise, Data Chat organizers can establish a foundation of trust and facilitate future collaborations and initiatives.
Some community collaborators shared their distrust of academic institutions. For example, one of our collaborators had been unhoused while attending a local university as a student: “if you’re at [university], and you go and you say, ‘Hey, I was struggling with homelessness,’ are they gonna do everything in their power to keep you like, on campus? And housing? Yeah, they don’t care.” Distrust of federal and county agencies that provide services also was noted, with many community collaborators sharing negative experiences, to the point where the conversation often strayed from data intake and data processes to anecdotes of experiences, and feelings of defeat such as, “there’s nothing I can do, nobody who can help you. You’re like a peasant. Who wants to consistently beg for something?” To build trust we found that we needed to practice respectful listening, show gratitude for honest expression, and acknowledge community collaborators’ generosity for agreeing to meet with us, especially when meetings took place on a university campus. By the end of the Data Chats, community collaborators shared that they felt positively about the experience, with one noting, “This is like a SNAP support group for the county.”
Trust was also built as we worked to create a comfortable environment in which we shared a meal and also distributed a small textured “fidget box” with blocks and play dough to keep hands busy during potentially stressful moments. This helped foster a calm, open environment. One community collaborator told us, “I like the play dough! I still have mine. That made us more open to talk to you, just knowing that you thought of us. That was nice.” Community collaborators commented that the food contributed to the environment: “I did have a good time last time and felt like I learned a lot. And the food? Yes, that brings us together.”
Curiosity
Researchers and medical practitioners list curiosity as an essential component to developing a real understanding of new problems (Adashi et al., 2019; Amon, 2015; Boudjelal, 2020). For these Data Chats, we set out to listen to community collaborators’ experiences with a spirit of curiosity, as this approach is vital to finding common ground and establishing effective collaboration. We recognized that everyone has their own experiences, thoughts, and opinions to share and approached Data Chats with excitement to hear what collaborators had to share, even if different collaborators experience conflict with one another or share stories that may not be related to the initial focus of the research. Regardless, these should be valued and investigated neutrally and curiously. In doing so researchers may discover better questions to ask and further relevant areas of focus.
By actively listening to community collaborators’ experiences with a curious mindset, facilitators and practitioners from data institutions can create an environment that promotes open dialogue and mutual respect. Active listening involves “restating the speaker’s message, responding empathically, and using prompts or repetitions to extract further information” (Louw et al., 2011) while refraining from judgment. When researchers approach community collaborators’ contributions neutrally and curiously, it creates a safe space for individuals to express themselves and share their insights without fear of being dismissed or overlooked.
Moreover, curiosity enables researchers to delve deeper into the topics and issues that community collaborators bring up. By valuing and investigating these contributions with an open mind, researchers can uncover new perspectives, uncover hidden nuances, and identify novel areas of focus that may not have been initially considered. The act of embracing curiosity allows researchers to go beyond their preconceived notions or predetermined research questions, leading to a more nuanced understanding of the community’s needs, concerns, and aspirations. Once community collaborators felt comfortable, they learned not only from the data sets but from each other as well: “I love the feedback sessions. I do like to know what other people go through and things of that nature. It’s good to know other people’s point of view. Things to think of.” Collaborators in the SNAP data chat became excited about the prospect of further research, and they wanted to explore questions together and hold other meetings outside of the research project: “I feel like you need to dive deeper into your research. Why is it that [Other county’s SNAP program] is so much better? Why do they answer the phone? . . . Why are our numbers so different?”
In this participatory research context, it is important to emphasize that the relationship between researchers and community collaborators is more than a mere subject-object dynamic. It is a partnership based on collaboration and shared decision-making. Adopting a curious approach facilitates the co-creation of knowledge and empowers community collaborators to actively contribute to the research process. By valuing and investigating their experiences with curiosity, researchers demonstrate a commitment to inclusivity, respect, and the co-production of knowledge.
Flexibility
Following the principles of connection/common ground, collaboration, respect, trust, and curiosity, we allowed Data Chats to be flexible. Even when we had an agenda for exploring data intake and data processes, we found that when following this principle, we sometimes had to prioritize respectful listening when collaborators wished to explore other topics that were not previously anticipated.
The principles of connection/common ground, collaboration, and curiosity feed into each other in a way that is mutually reinforcing. Leading with curiosity reinforces connection, collaborating creates common ground, connection makes collaboration easier etc. The abstract nature of these principles can make explicit rules harder to identify prior to beginning a project. Following the spirit of these principles in a way that is useful to all collaborators can mean flexibility and openness as it becomes important to give time and energy to any unanticipated needs of the group.
4. FAIR2 Data Chats in Action
Aligned with the PIT goal to develop civic-minded technologists, we envisioned FAIR2 as a tool for researchers but also students, so that future generations of social and data scientists can learn early in their careers the importance of social metadata and community context when analyzing big data. In this section we explore how FAIR2 Data Chats may enrich the data analyst’s understanding and use of data related to homeless services for youth facing homelessness.
HMIS (Homeless Management Information System) is a central database for tracking and managing housing and support services for people experiencing homelessness across a Continuum of Care (CoC). HMIS reporting is required by the U.S. Department of Housing and Urban Development for all CoCs, but each community determines how to implement HMIS reporting and prioritize resources for individuals and families experiencing homelessness. While designed for administrative purposes, HMIS data can be analyzed to shed light into the problem of homelessness, its impacts, and the effectiveness of programs to reduce homelessness. For example, an analysis of HMIS data found that engagement with public assistance programs following entry into homeless shelter reduced subsequent shelter use for adults in an urban community (F. G.-C. Richter et al., 2021). Another study using HMIS found that students had increased disciplinary incidents at school after a homeless shelter experience (Little, 2024). However, HMIS is far from a representative sample of all people in a CoC in need of housing services. Thus, we implemented a FAIR2 Data Chat to engage community collaborators in helping us understand the data generating process (data intake) and who is likely to experience homelessness but not be represented in the data.
4.1. Objective
We sought to better understand the data and metadata related to homeless services and its ability to characterize the population of young adults (aged 18-26) facing homelessness. We aimed to (1) learn about the data generating process– the data intake experience for homeless services– and (2) explore why some young people may not engage with housing services through this system. The ultimate goal is to inform data science projects involving HMIS records and address biases reflected in the data.
4.2. Facilitation Data, Questions, and Partners
Based on our objective, we prepared a slide presentation to share with community collaborators which included data visualizations, questions about the data intake process, and a cognitive mapping exercise about the causes and consequences of homelessness as well as the decision to use homeless services. Simultaneously, we developed our team by first identifying trusted partner organizations within the community and determining how they would be involved (facilitators, hosts representing a meeting space, etc.).
Our team consisted of two members affiliated with the School of Social Work (faculty and graduate student), a member of a research center focused on Environmental Health, and the director of ThinkingCapp (https://www.thinkingcapp216.com), a non-profit organization focused on wellness and positive connections. The non-profit organization leader led participant recruitment efforts and communicated with potential participants to ensure eligibility and logistics to attend the meeting. We partnered with Northeast Ohio Coalition for the Homeless (NEOCH, https://www.neoch.org) and A Place 4 Me (https://aplace4me.org/), who generously shared recruitment material with potential community collaborators. NEOCH offered their space to hold the Data Chats.
The guidelines for the ethical conduct of research guided our planning as we developed a consent process and submitted it to our IRB. Partners who assisted with facilitation completed CIRTification, which is a community-specific ethical research course developed by the University of Illinois Chicago (Rieger, 2025). We created fliers that invited young people to join us for a “Community Data Chat on Data Intake for Homeless Services,” stating clearly the inclusion criteria, meeting location and dates, as well as the offer of a gift card in recognition of collaborators’ time and expertise (see Figure 3 and Figure 4).
4.3. Community Collaborators - Data Chat Participants
We specifically sought to engage with young people who had previous HMIS data intake experience but were currently housed (interaction with homeless services in the last 4 years but not in the past month). This approach was taken to avoid placing undue burden on individuals who may be actively navigating the immediate challenges of homelessness—such as securing food, shelter, and safety. We recognized that for those currently unhoused, participation in a reflective data discussion might not align with their urgent needs. However, meeting with collaborators who had engaged with homelessness services in the past allowed for a rich, meaningful discussion while honoring the dignity, time, and capacity of those most affected. We connected with about a dozen potential collaborators of which seven were able to attend the Data Chat. As a recognition for collaborators joining the Data Chat, we offered a $60 gift card for the first two-hour session and a $50 card for the follow-up one-hour feedback session.

4.4. Conducting the Data Chat
We considered physical and emotional comfort needs when conducting the Data Chat. First, we clearly communicated transportation information such as parking and nearby bus stops. To provide emotional comfort, we created a “fidget” box to give to collaborators as a gift, which contained tactile items like lavender-scented play dough, wooden blocks, and a rough sandpaper on the outside of the box. We began the session by serving a meal that was respectful of collaborators’ dietary needs, and planned an icebreaker activity to thoroughly introduce collaborators to each other.
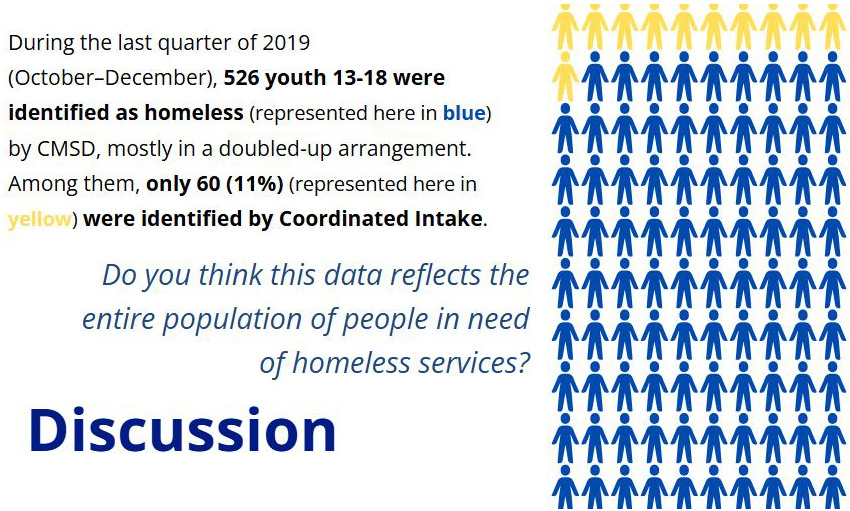
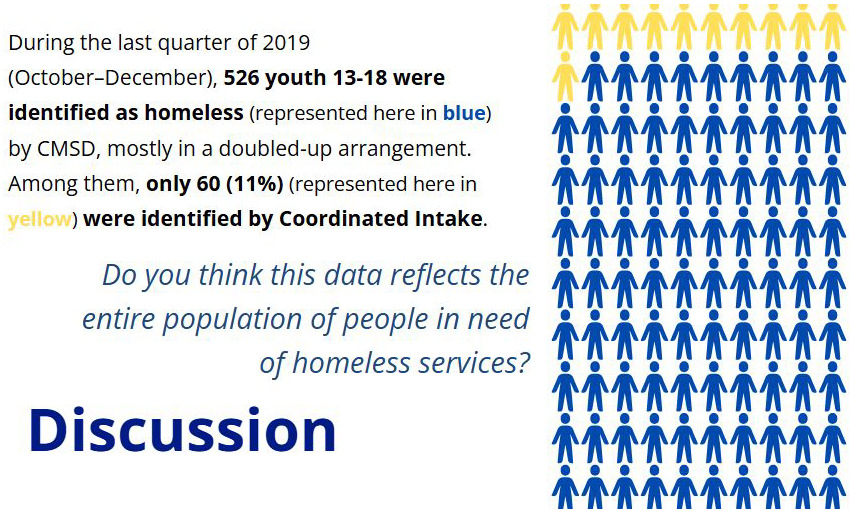
We underscored that our understanding of administrative data is incomplete without the experiential knowledge that community collaborators held as a collective, and that the experiential knowledge held by the group would enhance our ability to analyze the data to inform social good. As an ice-breaker, we all offered a response to “What neighborhood or community do you currently call home and what is something that you like about it?” This was followed by sharing graphics illustrating the number of young people who were seen in local administrative records at least once in 2017-2019. The graphs showed that about 30% of these young people had been identified in school records (Figure 3), but not HMIS, leading to a conversation about collaborators’ experiences with both systems. We also presented the different definitions of homelessness used by the agencies that collected this data, which to some extent influenced the difference in data recording.
Regarding the data intake process for homeless services, we provided the following questions for collaborators to discuss:
-
Who entered the information you provided in the intake form or computer?
-
Were you offered an explanation for the need to gather this information from you?
-
Do you think the intake of this data is necessary to provide the appropriate services?
-
If you have enrolled in other assistance programs, do you find that the data intake process is more demanding for one program than another?
4.5. Insights and Themes to Inform Data Analytics
The Data Chat contributed to each of the FAIR2 principles as follows:
Frame: Insights from community collaborators regarding the data intake process helped contextualize the way in which administrative data is generated. Table 1 provides themes derived from the Data Chat conversations and their associated quotes. Collaborators not only described the intake process but provided ideas about how to improve it for the benefit of young people experiencing homelessness.
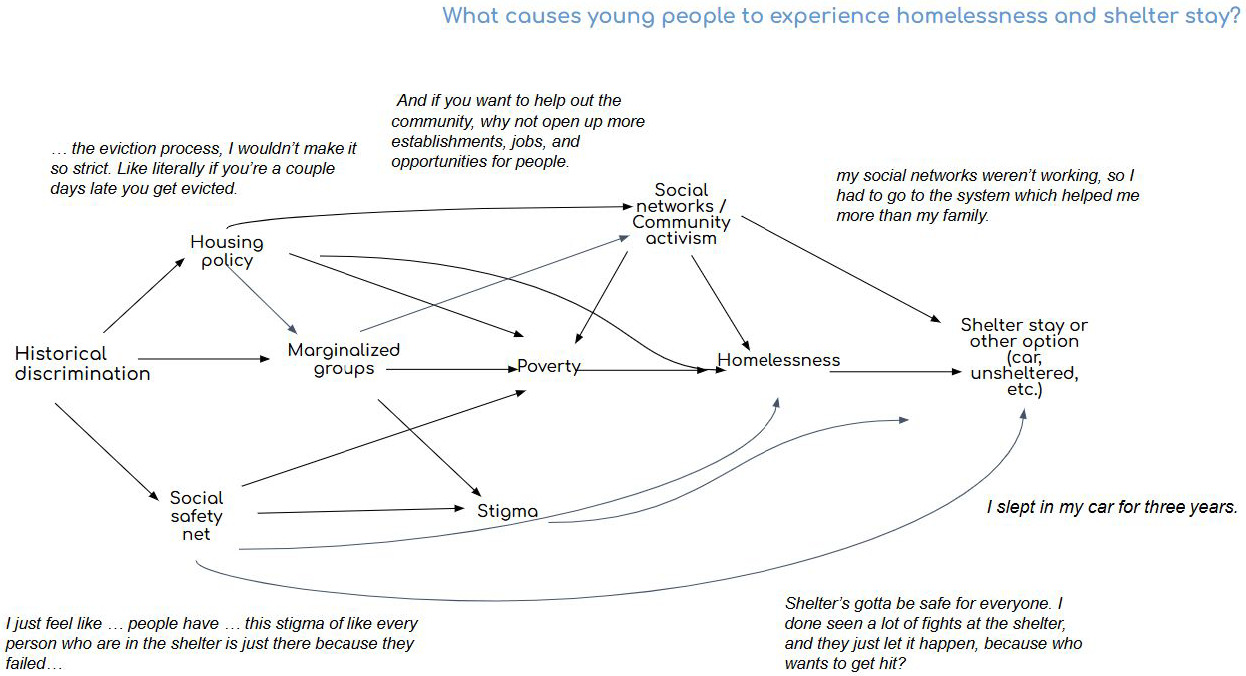
Articulate: Community collaborators spoke about what causes homelessness and influences their decision to seek or not homeless shelter. These insights were synthesized into themes relating to causal statements (Table 2) which then contributed to the design of a causal graph (Figure 5).
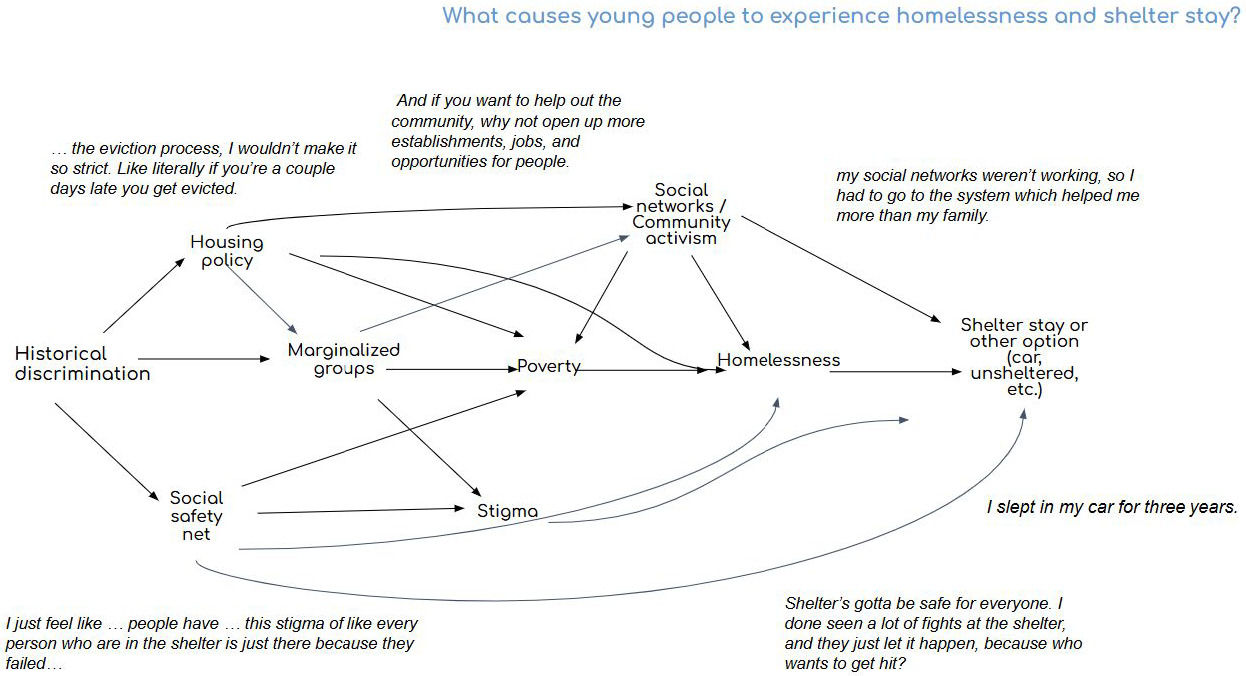
Identify: Here, insights of community collaborators helped us identify potential biases that may transfer to the data analytics if they are not recognized in the administrative data. Data analytics based on administrative data for homeless services like shelter or school services will exclude those who feel unsafe in shelter, stigmatized, or over monitored.
Minoritized populations are likely overrepresented in administrative records for homeless services. The causal graph in Figure 4 makes it clear that race is not a personal trait, but a reflection of discrimination, which is a system trait. This is important to reference if using race to characterize individuals who experience homelessness.
Missingness in administrative records cannot be assumed “at random.” Missingness may reflect safety concerns or distrust in the system that intersect with discrimination based on race or gender identity, as we heard from community collaborators. These insights were valuable in a study that aimed to estimate the size of the population of youth experiencing homelessness, by leveraging integrated data systems and Multiple Systems Estimation (MSE) (Fischer et al., 2024). MSE derives estimates of a population based on multiple, incomplete, and overlapping lists of subjects. The method assumes homogeneity -that individuals have an equal probability of appearing in a list - an assumption violated given Data Chat insights. Thus, we opted to provide estimates stratified by age group, race, and gender identity, where missing patterns within each group may deviate less from homogeneity. This exemplifies how experiential knowledge can identify potential biases and guide decision making regarding the data analytic process.
Report: After we had synthesized the information gathered at the FAIR2 Data Chat, we met with all community collaborators, either in person or virtually. We shared with them models, themes, and lessons from the Data Chats and sought out their feedback. We also shared these results with the community partners that helped us connect with community collaborators.
Ensuring community voices are accurately captured is crucial, and this process also allows collaborators to see how their experiential knowledge has come together to inform data analytics. Table 3 provides examples of how data analytics performed by student or professional analysts can be enriched with FAIR2 Data Chats for the benefit of the public interest.
The Data Chat discussed in this study engaged with seven community collaborators although more had expressed initial interest in participating. Future work may consider other strategies to increase access, such as selecting meeting locations that provide childcare or providing transportation to pick up and drop off collaborators from home. While holding Data Chats in university campuses may foster connectedness between institutions of higher education and their surrounding community, we also realize the tension between fostering relationships and ensuring inclusivity, as those facing greater challenges may be less able to attend.
Future work should also consider how to balance the needs of researchers to understand the data with the needs that community collaborators bring to the table. In a few instances, the conversation promoted networking and knowledge exchange among participants that they found useful to navigate the social safety net. These experiences suggest that fostering periodic networking meetings with community collaborators would be valuable for collaborators and researchers, although difficult to implement within the scope of a data science project.
Data You Can Use (DYCU) in Milwaukee’s motto is “no data without stories, no stories without data” (Cohen et al., 2022). This philosophy ties in well with the goals of the FAIR2 framework and underscores the importance of the learning gained from Data Chats.
5. Discussion
The logic of inference in social policy analysis can be described by this simple equation “assumptions + data → conclusions” (Manski, 2013). Here, assumptions refer to the statistical models applied to the data, but also the way we understand the data (the metadata), the extent to which data reflects our variables of interest, how these variables relate to each other, and the social process that generates the data. Given the considerable role of assumptions in social policy analysis points to the fact that data do not speak for themselves and that assumptions represent a source of subjectivity in social policy inference. Our work asks, whose expertise should we leverage to inform these assumptions? Will leveraging the experiential knowledge of those whose experiences are represented in the data in addition to traditional sources of scholarly knowledge lead to better informed social policy?
The field of participatory research has underscored the need to collaborate with stakeholders directly impacted by the social phenomena being studied and has developed a multiplicity of ethical and scientific approaches to produce research in collaboration with community stakeholders (Vaughn & Jacquez, 2020). We build on the progress made in the field by introducing FAIR2 Data Chats as a novel participatory research tool specifically designed to integrate experiential knowledge into data analytics for the public interest. Designed to inform the metadata, data, and methods within the FAIR2 framework, Data Chats provide structure and flexibility to the process of learning from community collaborators to inform social data analytics for the public good.
FAIR2 Data Chats also advance the field of data science for social good by introducing social metadata, which helps researchers recognize societal biases embedded in social interactions that produce data. With FAIR2 Data Chats, researchers can identify why certain groups, like youth avoiding shelters due to stigma, are missing from administrative records, thus challenging the missing at random assumption in data analytics. Furthermore, community insights inform more accurate system models which don’t require participants to have statistical expertise and thus, make for a more democratic exchange of knowledge.
No matter how big the data, ignoring experiential knowledge to inform social metadata and assumptions can lead to exacerbating disparities. The failure of healthcare algorithms to accurately identify the needs of Black patients, by using health costs as a proxy for health needs (Obermeyer et al., 2019), illustrates the critical need for participatory tools like FAIR2 Data Chats to inform data analytics. Experiential knowledge-based insights, articulated through community-informed graphical models, would have likely flagged health costs as a biased proxy for health needs, prompting analysts to adjust their modeling assumptions and ultimately avoiding algorithm scores that denied healthcare to marginalized patients.
The careful attention to FAIR2 Data Chat principles of common ground, trust, respect, curiosity and flexibility, lends to learning beyond what the analyst thought would be relevant for the analysis of data. When felt heard, community collaborators may voice concerns with social services and discrimination that were not planned in the discussion. This in turn may point analysts to focus on related research questions, thus bringing the research closer to the needs of the public, particularly those most marginalized in society.
In conclusion, FAIR2 Data Chats, guided by the principles of connection/common ground, collaboration, respect, curiosity, and flexibility, offer a valuable approach for researchers and students in data science to gain a deeper and more realistic understanding of data and analytics needed to advance the public interest. As society continues to grapple with the ethics of AI tools that learn from big data, FAIR2 Data Chats offer a participatory approach to bridge the gap between data technologies and the complex social realities associated with the data. Ultimately, the value of this approach lies in its ability to collaborate with those represented in the data as co-creators of knowledge, ensuring that data-driven decision-making truly serves rather than hinders the public interest.
Acknowledgements
We thank our community collaborators who wished to be named in the following ways, as well as those who wished to remain anonymous: Bre, Ebony Stephens, Marilyn, Adrieana Brothers, Sydni, Jameela, Shae, Wes, and Hannah Gates. We also thank the PIT-UN Community-Academic Advisory group at Case Western Reserve University for their insightful contributions. This work was generously funded by grant #015865 from the Public Interest Technology University Network - New America Foundation.